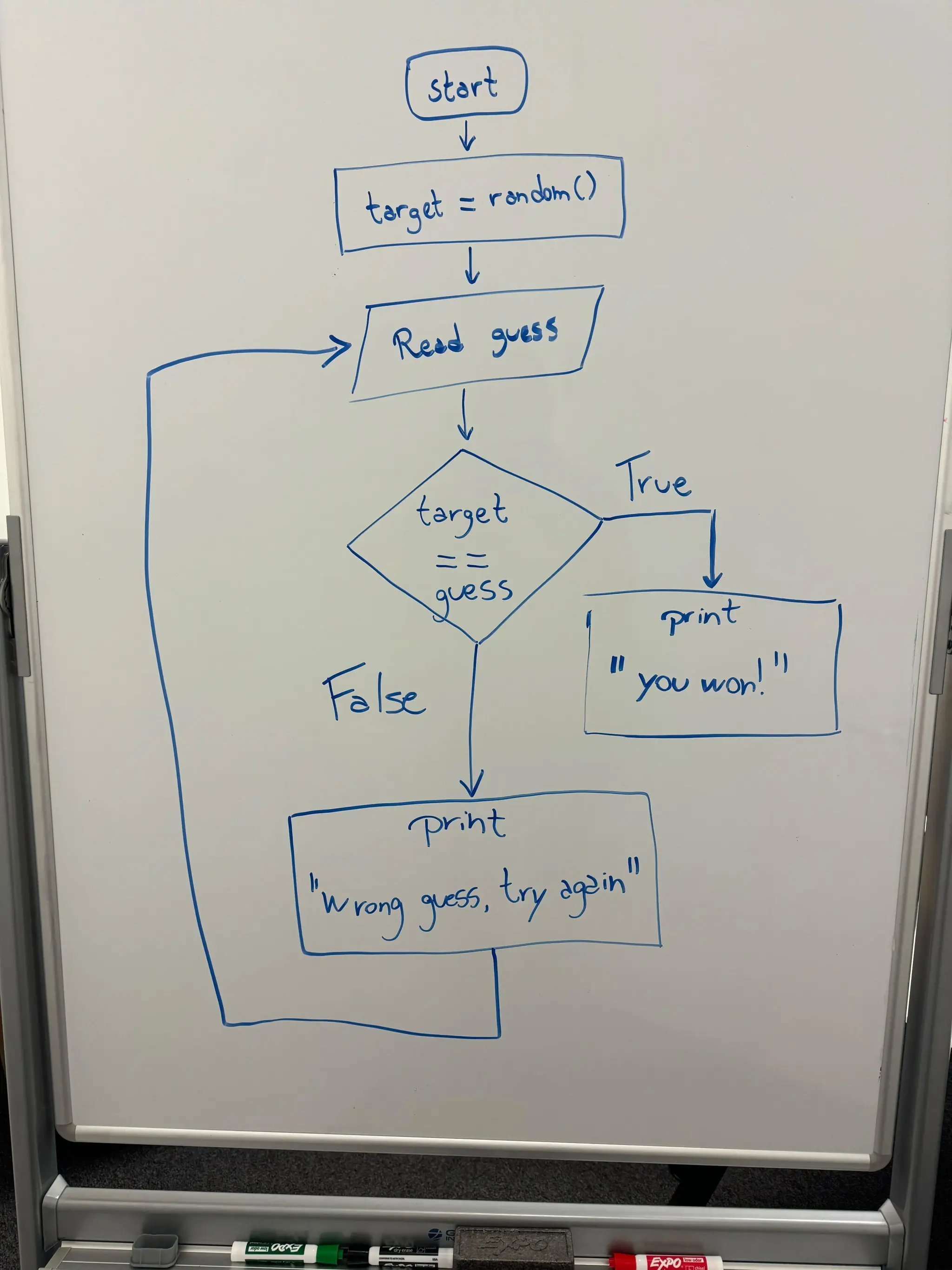
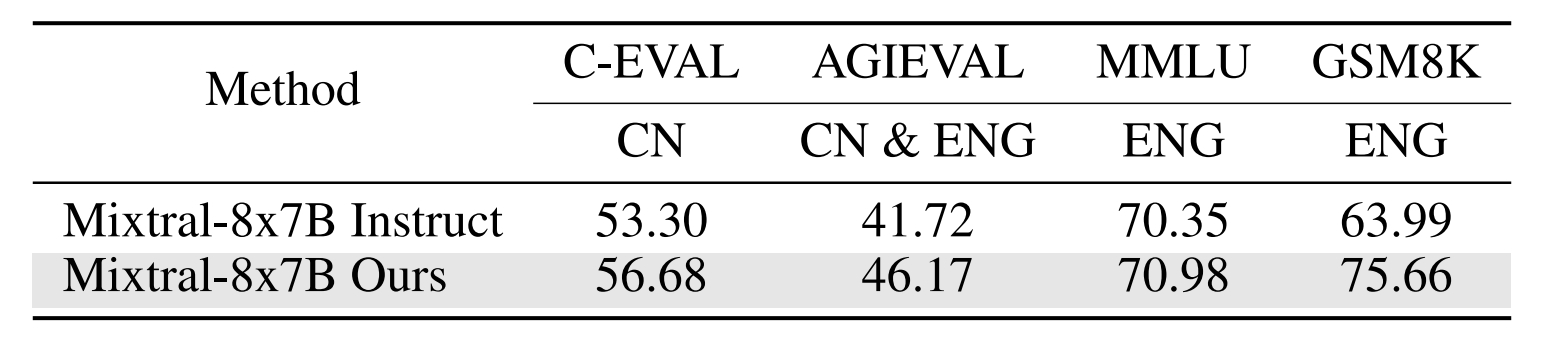
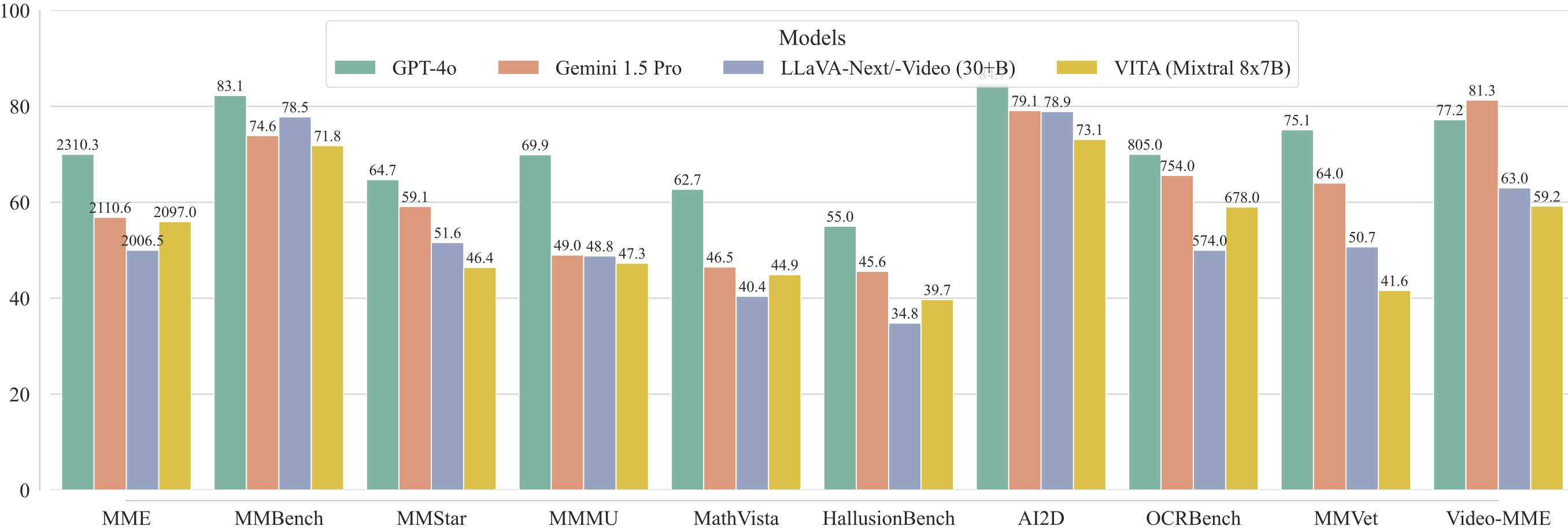
Math:
请帮我求解这个问题。
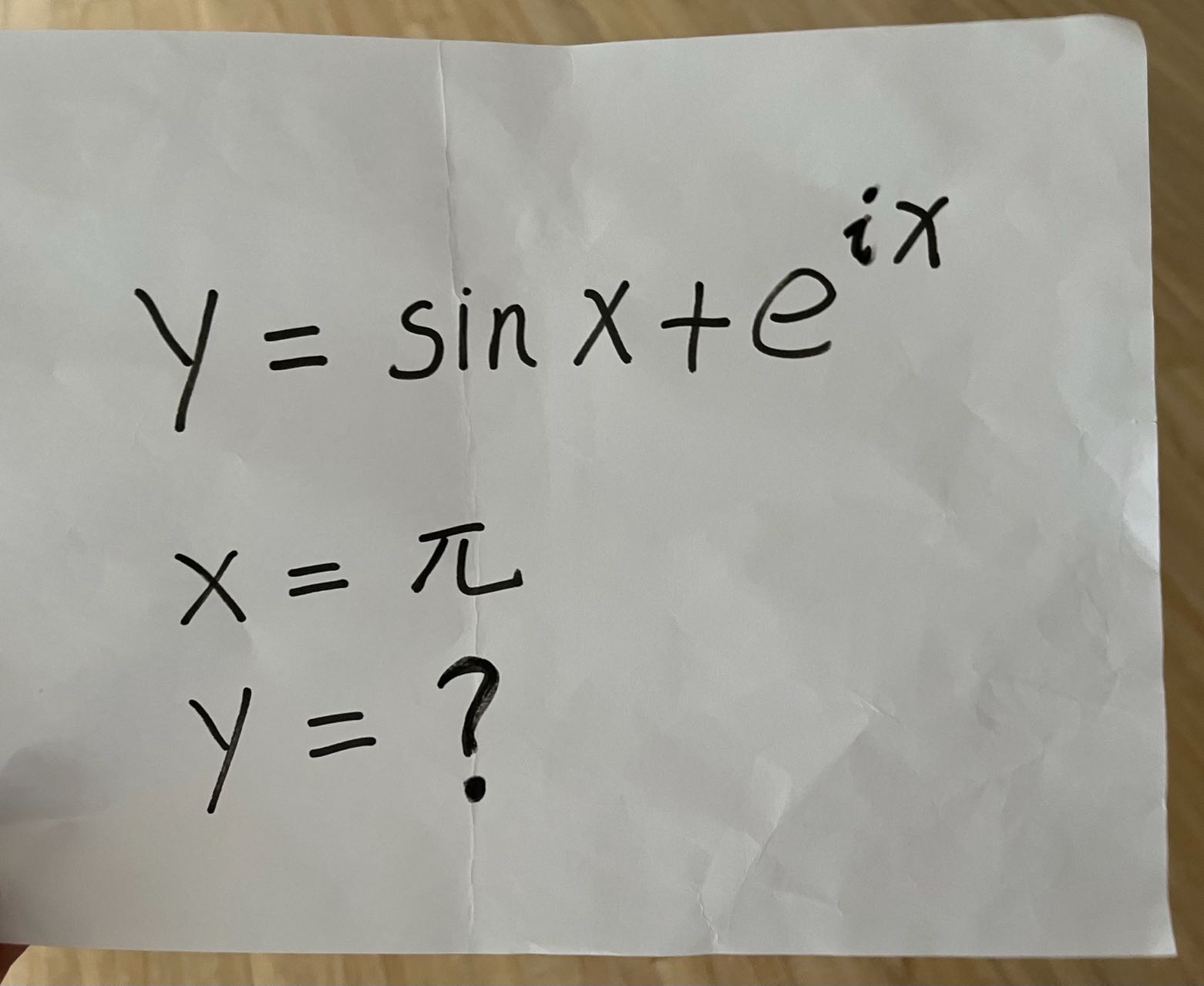
VITA:
这张图片展示了一张手写的数学问题。具体内容如下:
1. 题目:
[y = \sin x + e^{ix}]
2. 条件:
[x = \pi]
3. 问题:
[y = ?]
### 解题过程:
1. 首先,我们需要计算 ( \sin x ) 和 ( e^{ix} ) 在 ( x = \pi ) 时的值。
2. 对于 ( \sin x ),当 ( x = \pi ) 时,( \sin \pi = 0 )。
3. 对于 ( e^{ix} ),我们需要使用欧拉公式 ( e^{ix} = \cos x + i \sin x )。
- 当 ( x = \pi ) 时,( \cos \pi = -1 ),( \sin \pi = 0 )。
- 因此,( e^{i\pi} = -1 + i \cdot 0 = -1 )。
4. 所以,当 ( x = \pi ) 时,( y = \sin x + e^{ix} = 0 + (-1) = -1 )。
### 答案:
[y = -1]